Example 6d: Bayesian Network 'Student Model' : P( I | D=0, L=1, S=0)
Example 6d: Bayesian Network 'Student Model' : P( I | D=0, L=1, S=0)
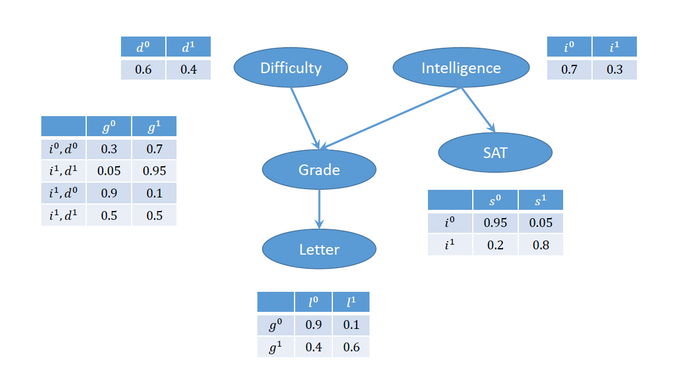
DAG of Bayesian Network 'Student Model'
Andrew D. Gordon, Thomas A. Henzinger, Aditya V. Nori, and Sriram K. Rajamani. 2014. Probabilistic programming. In Proceedings of the on Future of Software Engineering (FOSE 2014). ACM, New York, NY, USA, 167-181. DOI=10.1145/2593882.2593900 doi.acm.org/10.1145/2593882.2593900
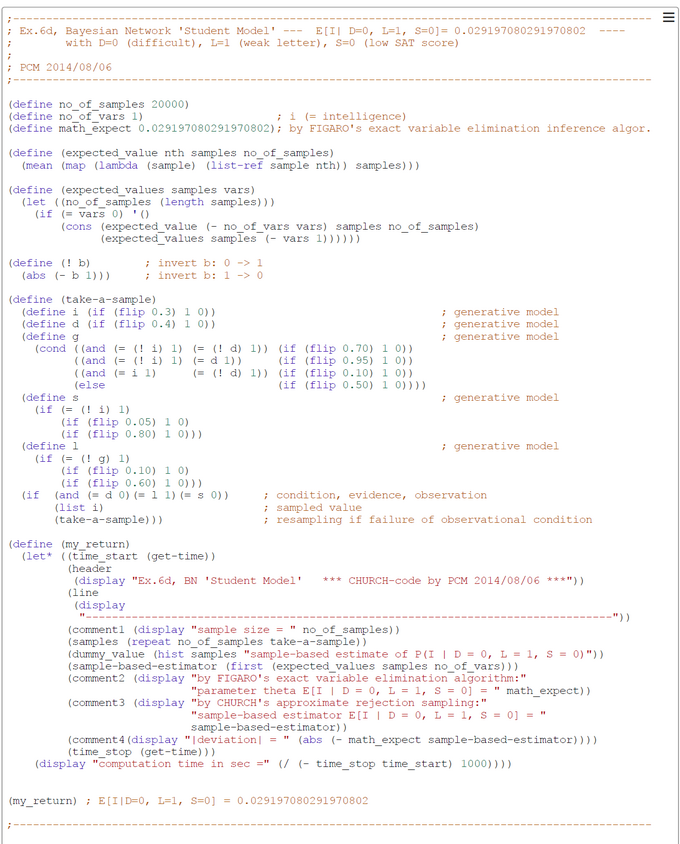
Ex6d: CHURCH-Code for Bayesian Network 'Student Model' and inference P( I | D=0, L=1, S=0)
The generative model of the functional CHURCH program is contained in the CHURCH function "take-a-sample". We chose the conditional P( I | D=0, L=1, S=0) = P(Intelligence | easy_course, weak_letter, SAT=low) to study the precision and efficiency of our simple rejection sampling scheme, because P( I=1 | D=0, L=1, S=0) <= 0.05.
Here is a summary of the domains due to the modifications of Gordon et al. (2014):
Val(D) = <d0, d1> = <easy, hard>
Val(I) = <i0, i1> = <non smart, smart>
Val(G) = <g0, g1> = <A, B+C> = <excellent, good+average>
Val(S) = <s0, s1> = <low score, high score>
Val(L) = <l0, l1> = <strong_letter, weak_letter>
The number of samples was set to 20000 in this run. This number could in principle be increased to get a better precision of estimates. The value of the variable math_expect (= parameter theta in the HOEFFDING inequality) was computed by the exact 'variable-elimination' inference method in the probabilistic programming language FIGARO. The sampling method used in our CHURCH-program is the simple-to-understand 'forward sampling'. The screen-shot presented was generated by using the PlaySpace environment of WebCHURCH.
The inferred E(I | D=0, L=1, S=0) = P(I=1 | D=0, L=1, S=0) is near 0.03 and much lower than its unconditional counterparts E(D) = P(I=1) = 0.30. So the verbal interpretation is "If your course is easy, you have a weak recommendation letter, a below average SAT score and my model is true, then I'm sorry to say that's very unlikely that you are a smart student".